The previous entry has concluded the problem with implementing reports based on different time zone, this time we will proceed with the possible workaround.
One thing we have realized is that, the time stamp being displayed on the report is changing according to the user locale, this means it occurs per user session. We definitely should take advantage of such feature, now we have to figure out a way to capture the time zone offset value for each user locale setting and use that to do our data conversion.
Luckily, OBIEE provides a list of pre-determined system variables. A lot of you may already be familiar with the likes of 'current_date', which returns the current time stamp. Here are a few other variables familiarly for the time zone locales:

So, let's try using 'timeZone' variable and see what I can get out of it. The proper syntax for calling this variable is '@{session.timeZone}', which can be used in column formula, filter values and prompts. Now I am just creating a new column in the report with this variable, it should return the time zone name in text format, the values will be exactly what you choose in your locale drop down list.

My idea is that, since most of the locale names are in text format and it tells you the offset values such as '(GMT-07:00) Arizona', I will then just take this value and substring it so it will only have the part after '-0' and be 3 digit long, and then convert the result into integer. I then get my offset values. The good thing about this is that, the value changes dynamically based on user's locale setting. I save myself from having to mess with session authentication. The only though, is that there are 2 locales names: '(GMT) Casablanca, Monrovia' and '(GMT) Greenwhich Mean Time: Dublin, Edinburgh, Lisbon, London' do not have any numeric implications. In these 2 cases, I will just change the text 'GMT' to 'GMT +00:00' with a case statement.
So putting all these thoughts together into a formula, I then create a new column that returns the offset value with the following statement:
cast(Substring(case when '@{session.timeZone}' = '(GMT) Casablanca, Monrovia' then '(GMT+00:00) Casablanca, Monrovia' when '@{session.timeZone}' = '(GMT) Greenwhich Mean Time: Dublin, Edinburgh, Lisbon, London' then '(GMT+00:00) Greenwhich Mean Time: Dublin, Edinburgh, Lisbon, London' when '@{session.timeZone}' = '' then '(GMT+00:00) Default' else '@{session.timeZone}' end From 5 for 3) as int)

Now the latter part '@{session.timeZone}' = '' then '(GMT+00:00) Default' was simply my attempt trying to take into consideration when user locale is set 'Default'. This however, has been proven to not work. But for now, leave it as it is.
Moving on, let's set the locale to be Arizona time:

And run the report:

As you can see, now the offset values and time zone columns are both reflecting what the time zone locale should be..In my case, the offset value is -7.
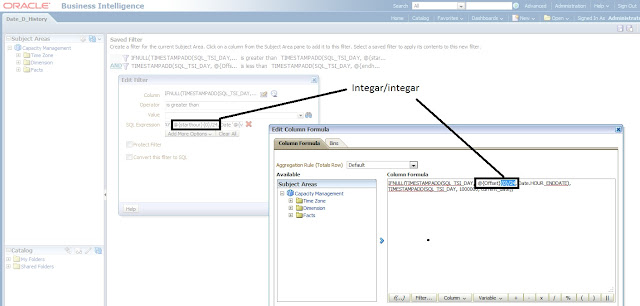
So I need to apply this offset value into my date and hour filters in order to take Arizona time into consideration. In my case, it is to edit the filter column formula where the original number divided by 24 would be replaced by the offset value. From the below screenshot, you will see a big cast statement divided by 24 within the timestampadd function. The exact reason of such set up can be read here if you care, but I digress.

Like I said from the previous post, this is a workaround, which doesn't quiet get it at 100%. One of the main issue of this solution is that it doesn't take daylight saving changes into consideration. This can be a big problem in the long run as daylight saving is one of the most complex thing to tackle. Nevertheless, having timeZone session variable is really handy, it opens more possibilities. Now with the tools we have, I am exploring into other solutions that might be able to deal with this requirement more efficiently.
I think I have found one! My first round of testing looks very promising.
Stay tuned!
Until next time